

The convergence engine for outcome engineering.
The convergence engine for outcome engineering.
Escape AI Pilot Purgatory.
Engineer AI Agent Outcomes.
Escape AI Pilot Purgatory. Engineer AI Agent Outcomes.
Escape AI Pilot Purgatory.
Engineer AI Agent Outcomes.
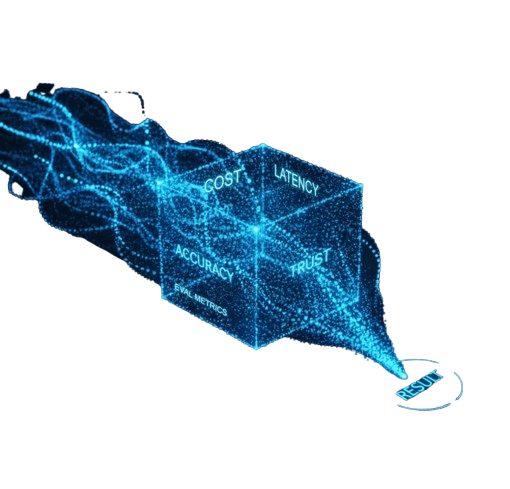
Balance accuracy, cost, latency, and trust with 20× to 1,000× more comparisons—on the same resources. Achieve engineered outcomes without the infrastructure bloat.

WHY CHOOSE
Why Choose Rapidfire AI?
Get to the best configuration without the guesswork — hyper-parallel experimentation that engineers outcomes across cost, accuracy, latency, and trust.
Hyperparallel Experimentation
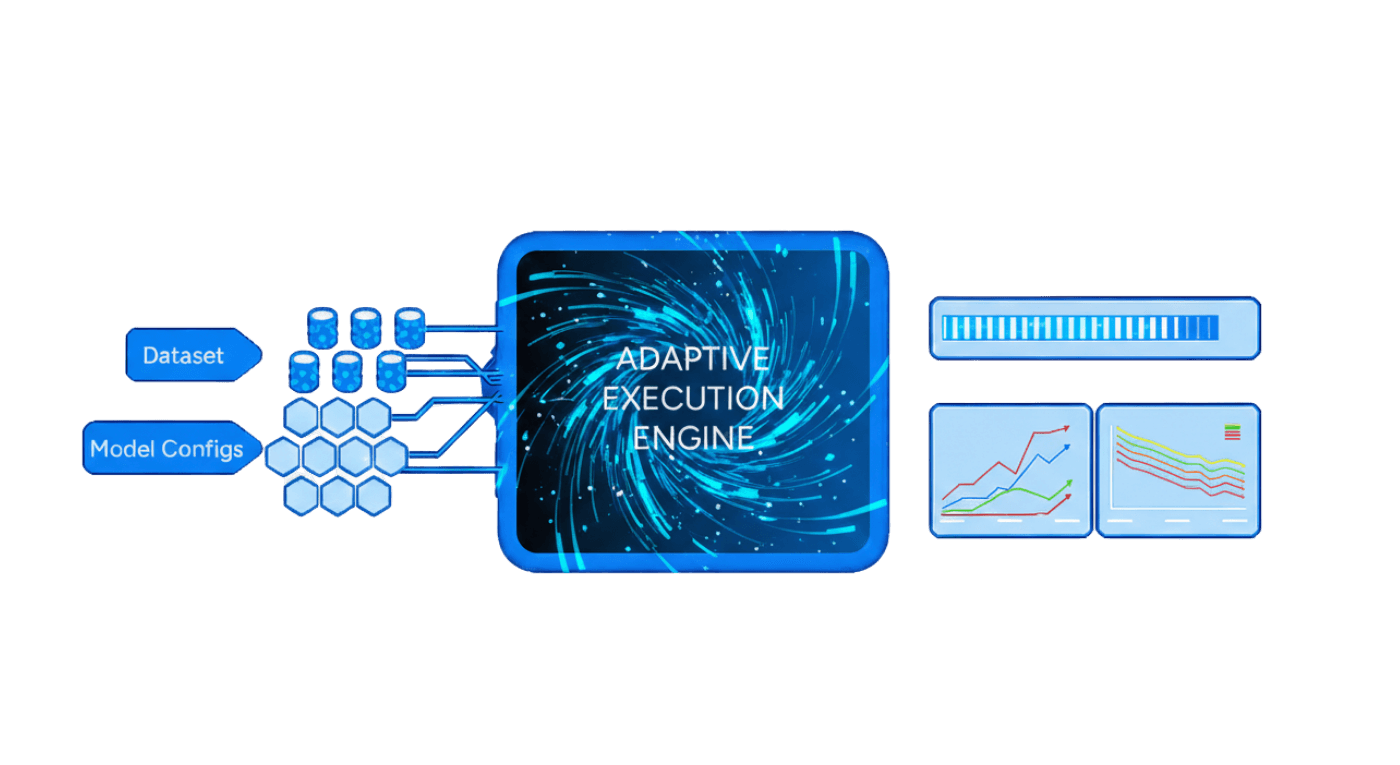
Stop wasting weeks manually turning knobs (prompt schemes, RAG specifics, chunking). With RapidFire AI, you can stress-test 1000+ configurations simultaneously to find your optimal model in a single pass.
Real-Time Interactive Control
Side-by-side monitoring of all config metrics. Stops underperforming configs. Clones and modifies high-performing configs on the fly.
Automated Optimization
Orchestrates end-to-end execution and engineers outcomes with complete transparency and control.
WHY CHOOSE
Why Choose Rapidfire AI?
Get to the best configuration without the guesswork — hyper-parallel experimentation that engineers outcomes across cost, accuracy, latency, and trust.
Hyperparallel Experimentation
Stop wasting weeks manually turning knobs (prompt schemes, RAG specifics, chunking). With RapidFire AI, you can stress-test 1000+ configurations simultaneously to find your optimal model in a single pass.
Real-Time Interactive Control
Side-by-side monitoring of all config metrics. Stops underperforming configs. Clones and modifies high-performing configs on the fly.
Automated Optimization
Orchestrates end-to-end execution and engineers outcomes with complete transparency and control.
WHY CHOOSE
Why Choose Rapidfire AI?
Get to the best configuration without the guesswork — hyper-parallel experimentation that engineers outcomes across cost, accuracy, latency, and trust.
Hyperparallel Experimentation
Stop wasting weeks manually turning knobs (prompt schemes, RAG specifics, chunking). With RapidFire AI, you can stress-test 1000+ configurations simultaneously to find your optimal model in a single pass.
Real-Time Interactive Control
Side-by-side monitoring of all config metrics. Stops underperforming configs. Clones and modifies high-performing configs on the fly.
Automated Optimization
Orchestrates end-to-end execution and engineers outcomes with complete transparency and control.
CUSTOMIZATION
Supports the Full LLM Customization Spectrum
Supports the Full LLM Customization Spectrum
Supports the Full LLM Customization Spectrum
Complete coverage from agentic engineering to fine-tuning
with systematic experimentation

Agentic Engineering
Features Included:
Optimize prompt schemes
Compare different agentic workflow structures
Compare multiple retriever and rerankers for RAG
Try alternate data pre-processing schemes
Automated production gates for grounding and latency
Agentic Engineering
Features Included:
Optimize prompt schemes
Compare different agentic workflow structures
Compare multiple retriever and rerankers for RAG
Try alternate data pre-processing schemes
Automated production gates for grounding and latency
Fine-Tuning & Post-Training
Features Included:
Supervised Fine-Tuning (SFT)
Direct Preference Optimization (DPO)
Group Relative Policy Optimization (GRPO)
Compare datasets, hyperparameters, and adapters
Historical Outcome Logging & Decision Tracking
Fine-Tuning & Post-Training
Features Included:
Supervised Fine-Tuning (SFT)
Direct Preference Optimization (DPO)
Group Relative Policy Optimization (GRPO)
Compare datasets, hyperparameters, and adapters
Historical Outcome Logging & Decision Tracking
SOLUTIONS
Engineer for Every Industry
Engineer for Every Industry
Engineer for Every Industry
From finance to research, bring systematic experimentation to mission-critical applications.






Integrations
Integrations & Ecosystem
Integrations & Ecosystem
Integrations & Ecosystem
Works seamlessly with your existing tools and infrastructure

Mistral

Qwen

DeepSeek
Gemini

Claude

OpenAI
Gemini
DeepSeek

PyTorch

Ray

Hugging Face

MLflow
What People are Saying
What People are Saying
What People are Saying



"Discoveredtheoptimalretrievalsettingsin20minutesinsteadofseveralhoursofmanualtesting."

Get Started in Minutes
Install via pip and start experimenting immediately with our Colab notebooks for RAG and Fine-Tuning workflows.
# Install RapidFire AI
pip install rapidfireai
# Start experimenting
rapidfireai init
Get Started in Minutes
Install via pip and start experimenting immediately with our Colab notebooks for RAG and Fine-Tuning workflows.
# Install RapidFire AI
pip install rapidfireai
# Start experimenting
rapidfireai init
Get Started in Minutes
Install via pip and start experimenting immediately with our Colab notebooks for RAG and Fine-Tuning workflows.
# Install RapidFire AI
pip install rapidfireai
# Start experimenting
rapidfireai init
UPDATES
What's New
What's New
Discover recent enhancements and powerful new capabilities.




Get Started Today
Install via pip or try it instantly in Google Colab.
Get Started Today
Install via pip or try it instantly in Google Colab.
Get Started Today
Install via pip or try it instantly in Google Colab.