

The Outer Loop: The Real Driver of AI Success
Written By:
Jack Norris
Published on
Jun 23, 2025
When people talk about deep learning, they usually talk about the inner loop—the elegant dance of forward passes, backpropagation, and gradient descent. This is the part that’s been endlessly refined over the years, from fancy loss functions to exotic optimizers to faster compilers. But if you’ve ever built AI applications in the real world, you know that the most critical decisions—the ones that actually determine success—don’t happen just inside the training loop.
They happen before and around it. This is the outer loop.
At RapidFire AI, we believe the outer loop is the most important–yet least optimized–layer of the modern AI stack. It governs the choices that define whether a model converges quickly or not at all, whether it delivers marginal improvements or breakthrough results. And yet, it’s still mostly held together by ad-hoc scripts, notebooks, and wishful thinking.
Let’s unpack what it is, why it matters, and how we’re changing the game.
The Outer Loop, Defined
The inner loop is what happens during training: a model makes predictions, compares them to the truth, and updates its weights. But the outer loop is the set of decisions that shape what gets trained and how. Which model architecture should you use? What learning rate, batch size, or prompt format? Which data augmentations? What metric best captures success in your use case?
Such experimentation determines how quickly you move from concept to high-performing solution, as we explained in our previous blog post.
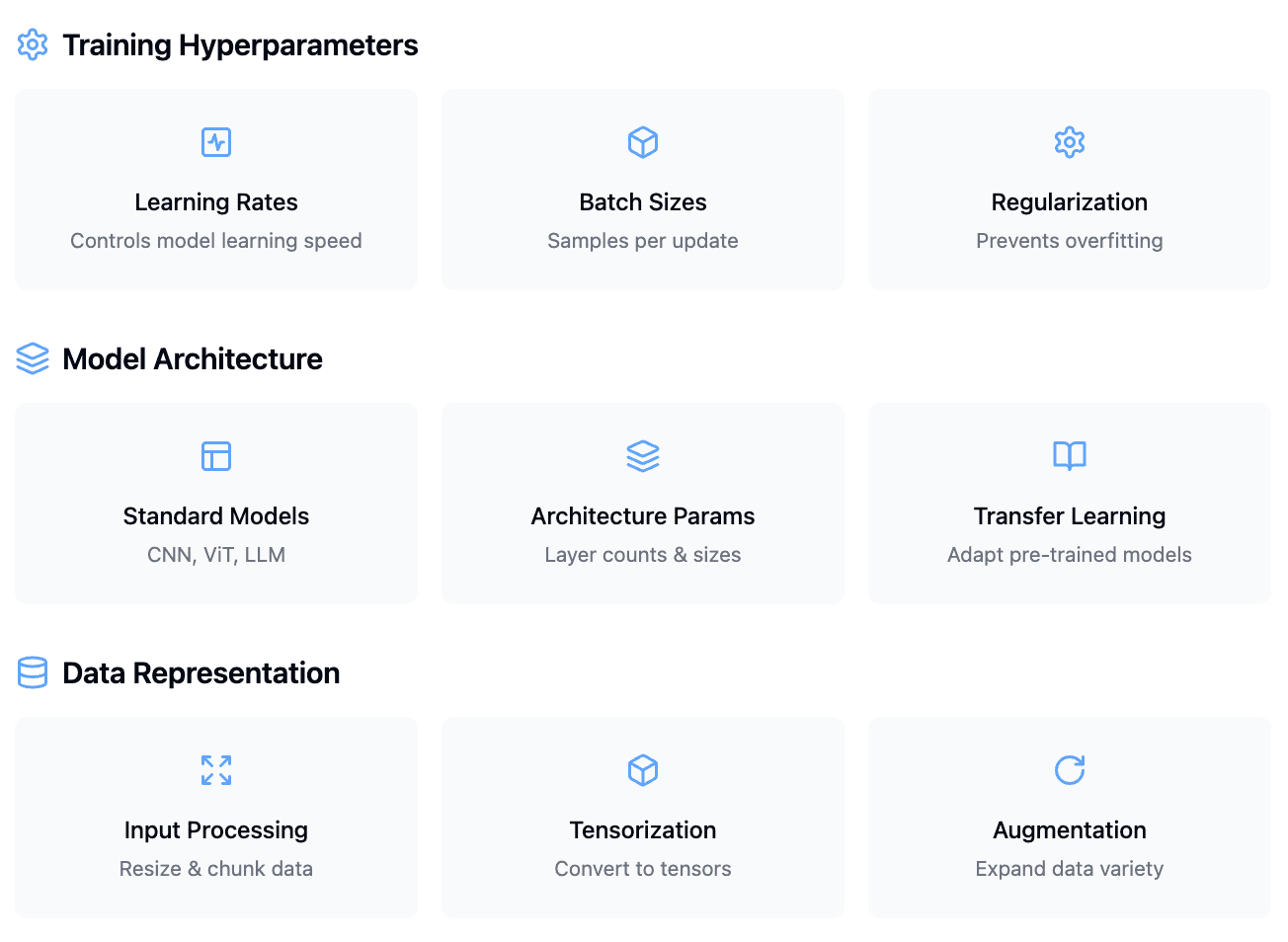
Fig 1. AI accuracy depends critically on three classes of experimental choices, each requiring careful exploration and tuning if one wants to maximize accuracy for their use case
Why It’s So Crucial Now
As AI scales, the cost of choosing the wrong configuration grows, as does the opportunity cost of not trying more or better configurations. You can waste thousands of dollars in GPU time training a model that was doomed from the start because of a poor hyperparameter choice or a bad data representation. Worse, you might never realize a better solution was just a few trials away, squandering your precious (labeled) data.
In research and in production, the outer loop is how most real progress happens. When teams make meaningful gains, it’s often because they explored a different architecture, introduced a new regularization technique, adapted a pre-trained model differently, or fine-tuned on more-relevant data. These aren’t inner-loop tweaks. They are outer-loop decisions.
And in today’s world—where AI agents can learn continuously, where LLMs/VLMs are being rapidly customized, and where costs are under scrutiny—nailing the outer loop isn’t just a nice-to-have; it is how you stay competitive.
The irony is that the most impactful part of the AI development process is also the most neglected today. Experimentation is slow, messy, spread across disparate tools, and hard to track. AI developers repeat the same runs with tiny variations, often without knowing what worked or why. Infrastructure gets wasted on low-yield training jobs. There’s no easy way to orchestrate or visualize the space of possibilities.
Thorough experimentation in accuracy-critical applications can lead to an overwhelming number of configurations. Consider the following (simplified) config space for a medical imaging example:
With just 8 hyperparameter combinations, 2 model architectures, and 2 data preprocessing strategies, we have 32 different configs. At, say, 24 hours per training run, that adds up to almost a month sequentially!
Alternatively, the team could pay for a lot more resources to increase the number of configs that can be run, but this often comes at prohibitively large costs.

Fig. 2 Exploration across the search space to improve accuracy can require significant time and resources. RapidFire AI accelerates this process by intelligently managing the process, enabling you to make real-time adjustments, and reallocating resources automatically so you reach the best models faster with less compute.
That’s why we built RapidFire AI.
RapidFire AI gives teams a way to explore, control, and optimize the outer loop like never before. With our software, you can launch hundreds of configurations in parallel on the same cluster, make real-time tweaks to models in flight, and systematically zero in on what actually works. Whether you're fine-tuning or training a vision model, or testing reinforcement learning policies, RapidFire AI helps you move faster—with fewer dead ends and dramatically lower GPU costs.
RapidFire AI, is a quantum leap in how you experience the outer loop. You no longer need to wait. You can kill the unpromising ones early, resume them later if you want, and dynamically clone, modify, and expand the set of promising ones—in real time, while training is still happening, without manually juggling separate clusters or jobs.
Here is a small sampling of how RapidFire enables a radical shift across some ubiquitous outer loop scenarios, spanning all types of knobs that affect AI accuracy: hyperparameters, model architectures, training process, and data representation.
1. Hyperparameter Tuning: Kill 80%, Clone the Top 5%
Before: You launched a grid or random search. Maybe 8 configurations ran in parallel on your 8-GPU cluster. You waited hours (or days!) to find out which ones performed well. Rinse and repeat, exhausting you and inhibiting you from exploring further.
Now: Launch a larger set—say 24, independent of the number of GPUs. Watch them all still learn together live. Stop the bottom 80–90% that clearly are not doing well after just an epoch. Their resources are automatically reallocated by RapidFire AI to the better performers. Clone the top 5%, explore new refined values around their knobs to expand the search space where it matters, shrink it where it doesn’t, and so on. This is real-time control for informed, responsive tuning without wasting GPU hours on dead ends. Handle all decision making with full control in the loop, semi-automate it with templates, or fully automate it with AutoML heuristics.
2. Architecture Comparisons: Parallelize Architectural Variants
Before: You trained one architecture, then another, and another—managing separate scripts, experiments, checkpoints. Even if you batched them, you were locked in until they finished.
Now: Launch many architecture variants in one go. See early-stage learning behavior in real time. Kill or pause weak ones early. Clone the strong ones, or tweak layer depth or normalization on the fly. You are not locked into a static plan—you are adapting dynamically. Freely compare across model sizes with differing inference latencies or memory footprint for edge deployment. Try variations of quantization-aware training or pruning schemes more quickly and not sacrifice accuracy after training.

Fig 3. Example showing the ability to compare variants, and with the real-time interactive control — pause, kill, or as shown above clone and directly modify code to inject additional variants into the process.
3. Parallel Exploration of Layers and Adapters with Real-Time Control
Before: You chose a layer to fine-tune or inserted a set of adapter modules for LoRA fine-tuning of an LLM, trained them, waited, repeated. Every variant has its own training run, hogging up all your GPUs, while you hope and pray for better accuracy early on.
Now: Quickly compare across multiple layers or adapter strategies launched together. Set up knobs for which set of adapters to use, layer-wise freezing, learning rate schedules. See which transfer patterns start converging quickly. Then shift GPU time toward the best candidates—while training is happening from the metrics dashboard itself.
4. Data Representation: On-the-Fly Augmentation and Resizing or System Prompt Tuning
Before: You preprocessed your images into multiple formats (e.g., different image sizes), or created separate system prompt structures for your LLM tuning, saved them all to disk, trained on each one separately.
Now: Define those as dynamic data knobs. Start with a smaller image resolution for faster training. If accuracy plateaus, clone your best model, increase image resolution midway, warm start it, and keep training. Test whether stronger augmentation hurts or helps. Compare across system prompt structures that give you maximum bang for your buck. No need to preprocess everything in advance or pontificate on what might work best. RapidFire lets you manipulate data settings as experiments are running.
The New Outer Loop Paradigm
The above scenarios illustrate the fundamental shift in AI experimentation that RapidFire AI enables. The outer loop used to be constrained by narrow task-level parallelism—scheduling jobs in a queue and waiting for each to finish with no dynamic comparison or control. With RapidFire, you gain hyperparallelism and real-time control, enabling:
Live pruning of unpromising runs
Dynamic cloning of strong candidates
Immediate steering of all kinds of knobs: hyperparameters, architectures, training details, and data settings
Reduced time-to-accuracy across the board
This isn’t just faster; it’s a fundamentally better way to explore. You're no longer a passive observer waiting on jobs—you’re an active participant inside your experiment loop.
Why It Matters
For teams building cutting-edge models or optimizing for production, this new outer loop means:
Lower GPU waste: Stop bad runs early
Faster iteration: No need to wait for entire sweeps to finish
More insight per dollar: Get more learning signal per experiment hour
Higher accuracy: By actively responding to what you see in training, you reach better results sooner
RapidFire.AI isn’t just a job scheduler or a wrapper—it’s a new paradigm of thinking about AI experimentation. The outer loop, once static and inflexible, is now a dynamic, responsive, and interactive playground. And that changes everything.
This Is the Future of Productive AI
If your models are underperforming despite investing in your precious data—or if you're spending too much time and money getting to good results to ship your use case—chances are the problem isn’t your model weights or optimizer. It’s your outer loop.
By investing in this overlooked layer, you can unlock more performance, more insight, and more progress. That’s what RapidFire AI is here to deliver.
Try RapidFire AI free today, and see what happens when your experimentation loop moves at the speed of your ideas.